Before I was a parent I never gave much thought to children's clothing, other than to covet a few of the baby shirts at T-Shirt Hell. Now that I have a two-year-old daughter, I have trouble thinking of anything but children's clothing. (Don't tell my boss!)
What I have discovered over the last couple of years, is that clothing intended for boys is fun, whereas clothing intended for girls kind of sucks. There's nothing inherently two-year-old-boy-ish about dinosaurs, surfing ninjas, skateboarding globes, or "become-a-robot" solicitations, just as there's nothing inherently two-year-old-girl-ish about pastel-colored balloons, or cats wearing bows, or dogs wearing bows, or ruffles. Forget about gender, I want Madeline to grow up to be a "surfing ninja" kind of kid, not a "cats wearing bows" kind of kid. An "angry skateboarding dog" kind of kid, not a "shoes with pretty ribbons" kind of kid.
Accordingly, I have taken to buying all of Madeline's shirts in the boys section, the result of (her boy-ish haircut and) which is that half the time people refer to her as "he". This doesn't terribly bother me, especially if she ends up getting the gender wage premium that people are always yammering about on Facebook, but it makes me wonder why such a stark divide between toddler boy shirts and toddler girl shirts. And, of course, it makes me wonder if the divide is so stark that I can build a model to predict it!
The Dataset
I downloaded images of every "toddler boys" and "toddler girls" t-shirt from Carters, Children's Place, Crazy 8, Gap Kids, Gymboree, Old Navy, and Target. Because each one had their shirts at a different (random) website location, I decided that using an Image Downloader Chrome extension would be quicker and easier than writing a scraping script that worked with all the different sites.
I ended up with 616 images of boys shirts and 446 images of girls shirts. My lawyer has advised me against redistributing the dataset, although I might if you ask nicely.
Attempt #1: Colors
(As always, the code is on my GitHub.)
A quick glance at the shirts revealed that boys shirts tend toward boy-ish colors, girls shirts toward girl-ish colors. So a simple model could just take into account the colors in the image. I've never done much image processing before, so the Pillow Python library seemed like a friendly place to start. (In retrospect, a library that made at least a half-hearted attempt at documentation would probably have been friendlier.)
The PIL library has a getcolors function, that returns a list of
(# of pixels, (red, green, blue))
for each rgb color in the image. This gives 256 * 256 * 256 = almost 17 million possible colors, which is probably too many, so I quantized the colors by bucketing each of red, green, and blue into either [0,85), [85,170) or [170,255]. This gives 3 * 3 * 3 = 27 possible colors.
To make things even simpler, I only cared about whether an image contained at least one pixel of a given color [bucket] or whether it contained none. This allowed me to convert each image into an array of length 27 consisting only of 0's and 1's.
Finally, I trained a logistic regression model to predict, based solely on the presence or absence of the 27 colors, whether a shirt was a boys shirt or a girls shirt. Without getting too mathematical, we end up with a weight (positive or negative) for each of the 27 colors. Then for any shirt, we add up the weights for all the colors in the shirt, and if that total is positive, we predict "boys shirt", and if that total is negative, we predict "girls shirt".
I trained the model on 80% of the data and measured its performance on the other 20%. This (pretty stupid) model predicted correctly about 77% of the time.
Plotted below is the number of boys shirts (blue) and girls shirts (pink) in the test set by the score assigned them in the model. Without getting into gory details, a score of 0 means the model thinks it's equally likely to be a boys shirt or a girls shirt, with more positive scores meaning more likely boys shirt and more negative scores meaning more likely girls shirt. You can see that while there's a muddled middle, when the model is really confident (in either direction), it's always right.
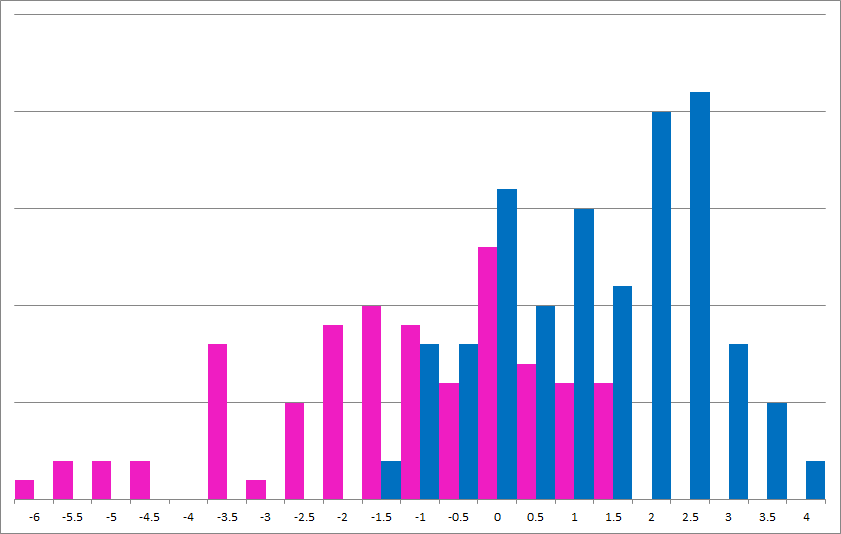
If we dig into precision and recall, we see
P(is actually girl shirt | prediction is "girl shirt") = 75%\ P(is actually boy shirt | prediction is "boy shirt") = 77%\ P(prediction is "girl shirt" | is actually girl shirt) = 63%\ P(prediction is "boy shirt" | is actually boy shirt) = 86%
One way of interpreting the recall discrepancy is that it's much more likely for girls shirts to have "boy colors" than for boys shirts to have "girl colors", which indeed appears to be the case.
Superlatives
Given this model, we can identify
The Girliest Girls Shirt (no argument from me):

The Boyiest Girls Shirt (must be the black-and-white and lack of color?):

The Girliest Boys Shirt (I can see that if you just look at colors):

The Boyiest Boys Shirt (a slightly odd choice, but I guess those are all boy-ish colors?):

The Most Androgynous Shirt (this one is most likely some kind of image compression artifact, the main colors are boyish but the image also has some girlish purple pixels in it that cancel those out):

The Blandest Shirt (for sure!):

The Most Colorful Shirt (no argument with this one either!):

Scores for Colors
By looking at the coefficients of the model, we can see precisely which colors are the most "boyish" and which are the most "girlish". The results are not wholly unexpected:
|
151.71
|
|
|
80.68
|
|
|
69.35
|
|
|
49.69
|
|
|
43.83
|
|
|
40.99
|
|
|
35.94
|
|
|
30.56
|
|
|
26.08
|
|
|
24.06
|
|
|
20.89
|
|
|
20.49
|
|
|
18.89
|
|
|
17.67
|
|
|
1.29
|
|
|
-17.37
|
|
|
-21.77
|
|
|
-29.95
|
|
|
-49.91
|
|
|
-56.4
|
|
|
-66.77
|
|
|
-69.52
|
|
|
-70.15
|
|
|
-82.17
|
|
|
-119.1
|
|
|
-175.2
|
|
|
-224.74
|
In Conclusion
In conclusion, by looking only at which of 27 colors are present in a toddler t-shirt, we can do a surprisingly good job of predicting whether it's a boys shirt or a girls shirt. And that pretty clearly involves throwing away lots of information. What if we were to take more of the actual image into account?
Coming soon, Part 2: EIGENSHIRTS