"How do you know if someone does Crossfit?"
"They build a RAG system about Crossfit!"
As my next project, I wanted to build a non-trivial RAG system. To do that, I needed a non-trivial dataset.
Every day for 20+ years, Crossfit.com has published a Workout of the Day ("WoD").
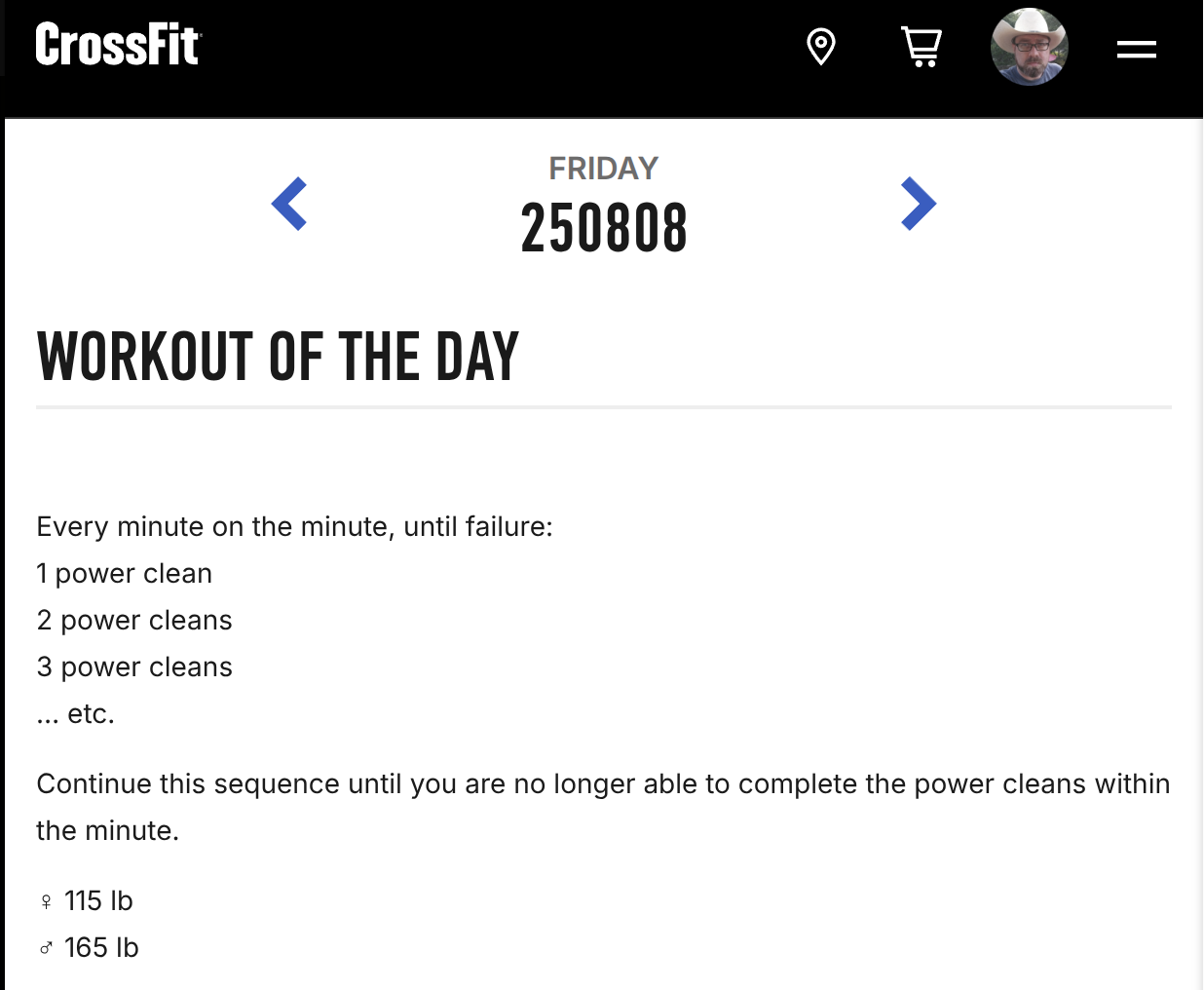
That seemed like it could make for an interesting retrieval system. (Interesting to me, anyway.)
To start with I downloaded them all.
Then I let Claude write some BeautifulSoup code
to get the raw workout text out of the HTML.
Then I wanted to extract the data from the raw text,
which I did with dspy (I do everything with dspy).
It looked something like this:
class ExtractMetadata(dspy.Signature):
workout: str = dspy.InputField()
movements: list[str] = dspy.OutputField()
equipment: list[str] = dspy.OutputField()
workout_type: WorkoutType = dspy.OutputField()
workout_name: str = dspy.OutputField()
one_sentence_summary: str = dspy.OutputField()
(The fields actually had more detailed descriptions than this, with e.g. guidance about how to extract the name and so on, but this was the basic shape.)
(I already had "date" from the raw data, so I didn't need the LLM to extract that.)
I stuck this all in a paradedb database (basically Postgres with bm25 and vector search).
I also added openai-small embeddings for both the full workouts and the one-sentence summaries.
At this point I started to think about the sorts of questions I wanted to be able to answer. Things like
- what is the workout Murph?
- when was the first time Murph was the workout of the day?
- how many times has Murph been the workout of the day?
- what are some workouts that have both pull ups and sit ups?
- how many workouts in 2025 have involved rowing?
- can you make me a workout that has swimming and pull ups?
To me this looked like a dspy.ReAct problem. To start with I gave it the following tools:
- hybrid search: for the "what is murph" it could hybrid search for 'murph' and use the top 5 workouts as context. this is a pure search query -> results tool
- duckdb text to sql: this would allow for aggregations / sorting by writing duckdb sql, to allow things like "when was the first murph" and "how many times"
- generate workout: this tool was itself a dspy RAG that finds the 5 "closest" workouts to the requested description and then uses them to create a new workout. (if this feels like an odd fit, it is, this is what I started with before the agentic RAG, and I just left it as a tool).
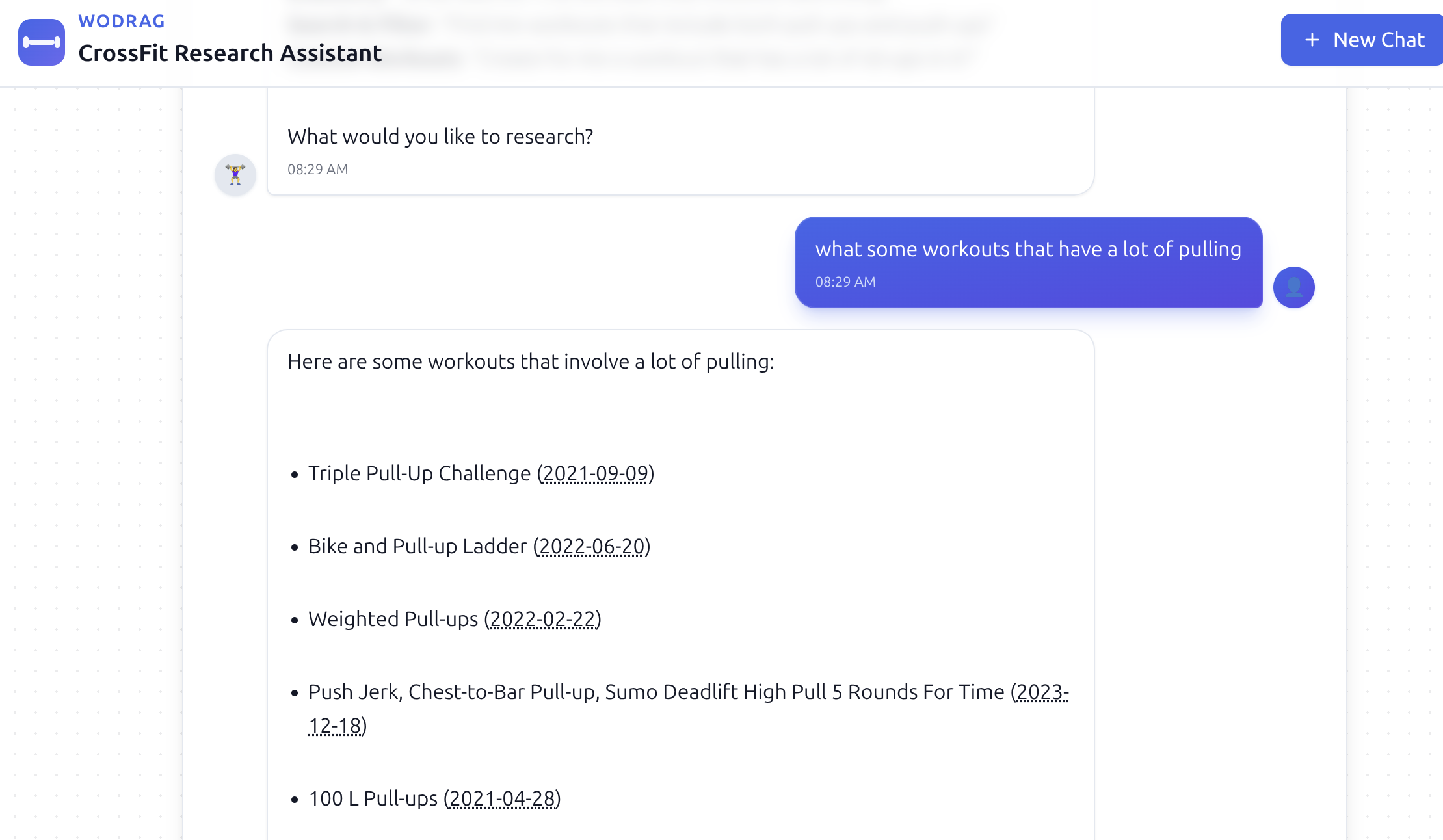
What I quickly discovered was that I had a lot of trouble tuning the hybrid search. Some queries really needed "semantic" search ("find me workouts that have a lot of pulling"). And some queries really needed keyword search ("find me workouts called murph"). Eventually I split these into two different tools "very_semantic_search" and "very_keyword_search" that used the same hybrid search code with different weights. And I let the ReAct agent choose which one to use depending on the query. This worked pretty well.
I also added another tool that was just "get workout by date" as this ended up being a common pattern.
While I was doing all this, I also built a web front-end. (Claude built a web front-end.)
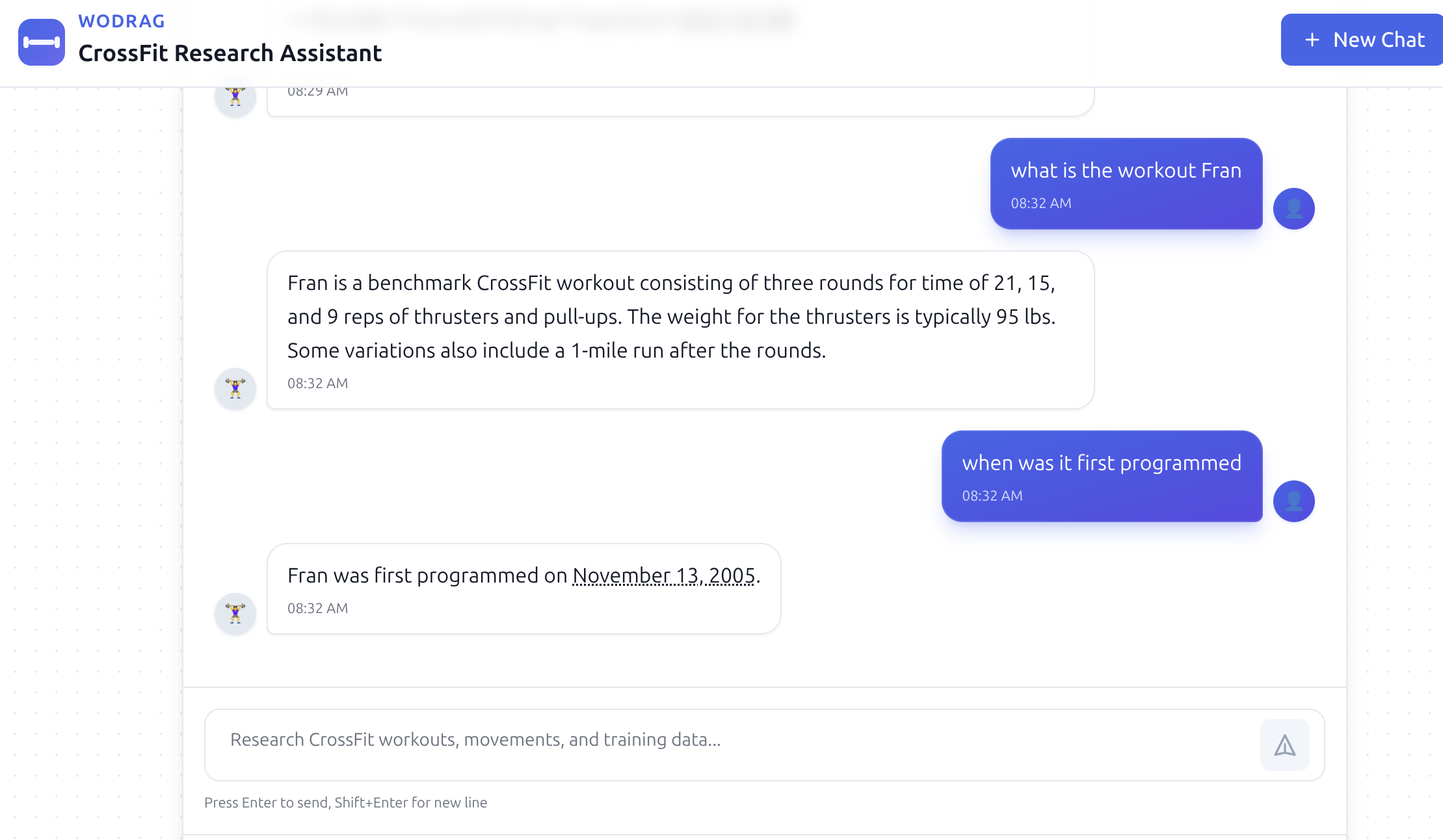
And implemented multi-turn conversation:
And this time I wanted actually to get some practice doing devops, so I containerized the app (frontend + backend + database), acquired a VPS and a domain name, triple-checked for security issues, and muddled my way through deploying it.
Behold: wodrag.com
(It's using my API keys for the LLMs, so be gentle.)
If you play with it you will find that it behaves unsatisfactorily in some ways. In particular, there are a lot of data issues, e.g.:
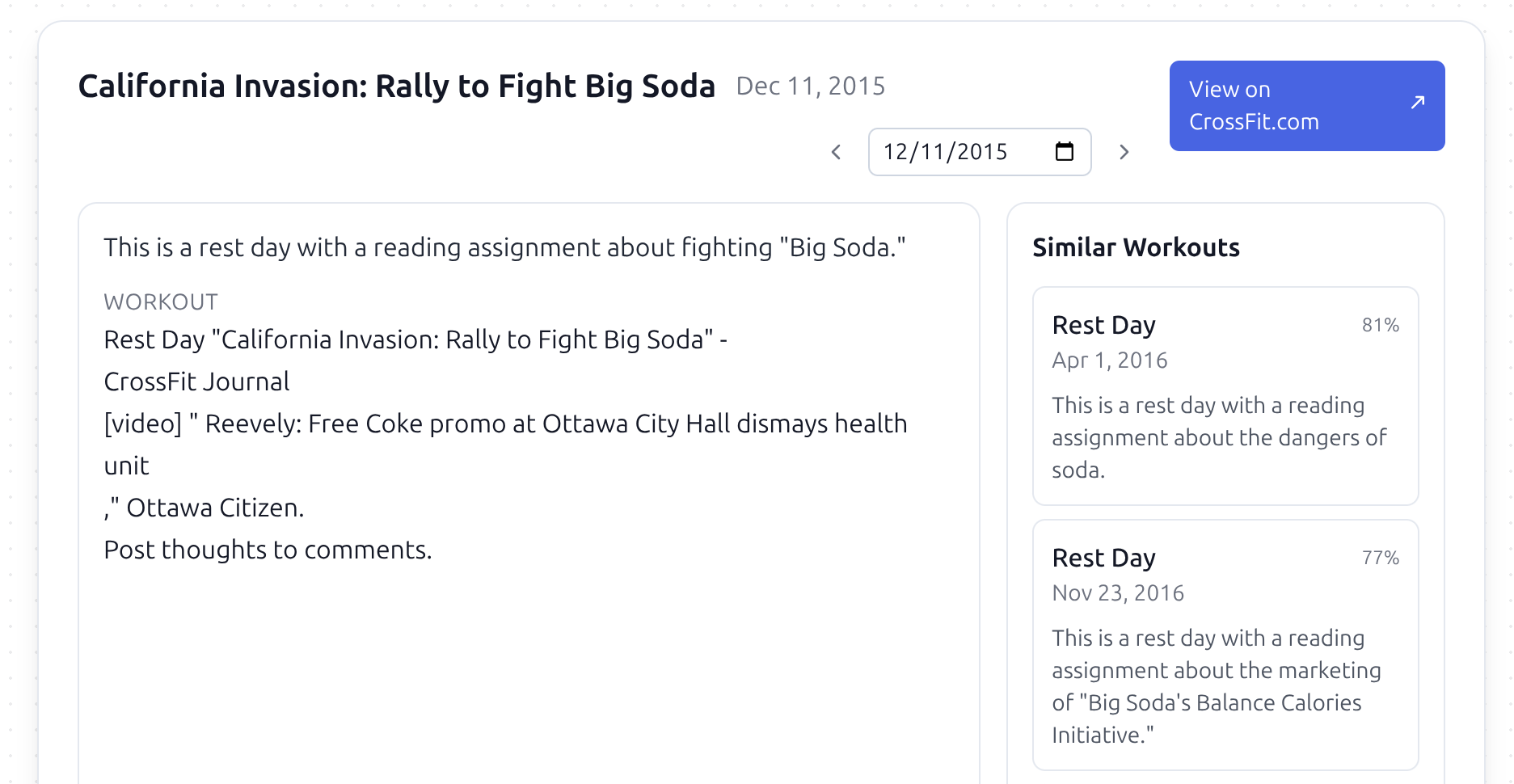
Here the name of the workout is wrong (it should be "Rest Day") and the original contained links that got mangled, leaving cruft like "[video]" as well as strange line breaks.
This tells me that we should have spent more time and thought on the data extraction and preprocessing. That will likely be my next project. (The other obvious improvement would be for the searches to return more results and then to implement some kind of reranker. That might also be a future project.)
In the meantime, you can check this one out on GitHub, although it's a little bit messy.